






该教程是本学期大数据与云计算课程的课程实验,希望能帮助到不知道如何下手的同学,同样也是对自己学习过程的记录,方便以后的学习
声明:该教程只是为了帮助大家完成本学期的实验,请不要直接将教程中的内容直接复制作为实验报告,务必按照自己的实际情况进行操作和编写,如若出现因复制教程内容导致实验报告雷同被查的情况,一概不负责
一、准备工作
开始之前,需要先完成Ubuntu系统下的Hadoop分布式集群安装,如果还未完成,可以先参考之前的这篇文章;如果一开始就使用的是单机版Hadoop,可以直接做实验,不用管前面这些配置,也不用跑去虚拟机上搭建一个分布式Hadoop集群
如果一开始就自己搭建了分布式Hadoop集群,那么在Windows上也要完成Hadoop环境的配置,因为在后续实验中我们需要在Windows上使用IDEA编写测试类来对Ubuntu中Hadoop的HDFS文件系统进行操作,所以Windows也要配置好Hadoop环境,不然会报HADOOP_HOME找不到之类的错误(Hadoop需要依赖JDK,就默认大家都已经安装了JDK)
1.1 Windows中安装Hadoop
如果是直接使用老师发的配置好的hadoop压缩包则只需要查看如何配置好环境变量即可,另外,建议Windows中安装的Hadoop和Ubuntu中安装的Hadoop版本一样,以免引起不必要的麻烦或是可能因版本不同引起造成的冲突问题
1.1.1 下载Hadoop
这个在之前的Ubuntu下搭建Hadoop分布式集群教程中已经提到过,就不再赘述了
注:我使用的是Hadoop3.2.3
1.1.2 解压Hadoop
新建一个文件夹,用来存放Hadoop
然后将下载好的压缩包(后缀名就是tar.gz,不用怀疑)移动到这个文件夹下,**以管理员身份解压**到当前文件夹
1.1.3 设置环境变量
依次点击计算机->属性->高级系统设置->环境变量
然后进行以下环境变量配置
添加HADOOP_HOME
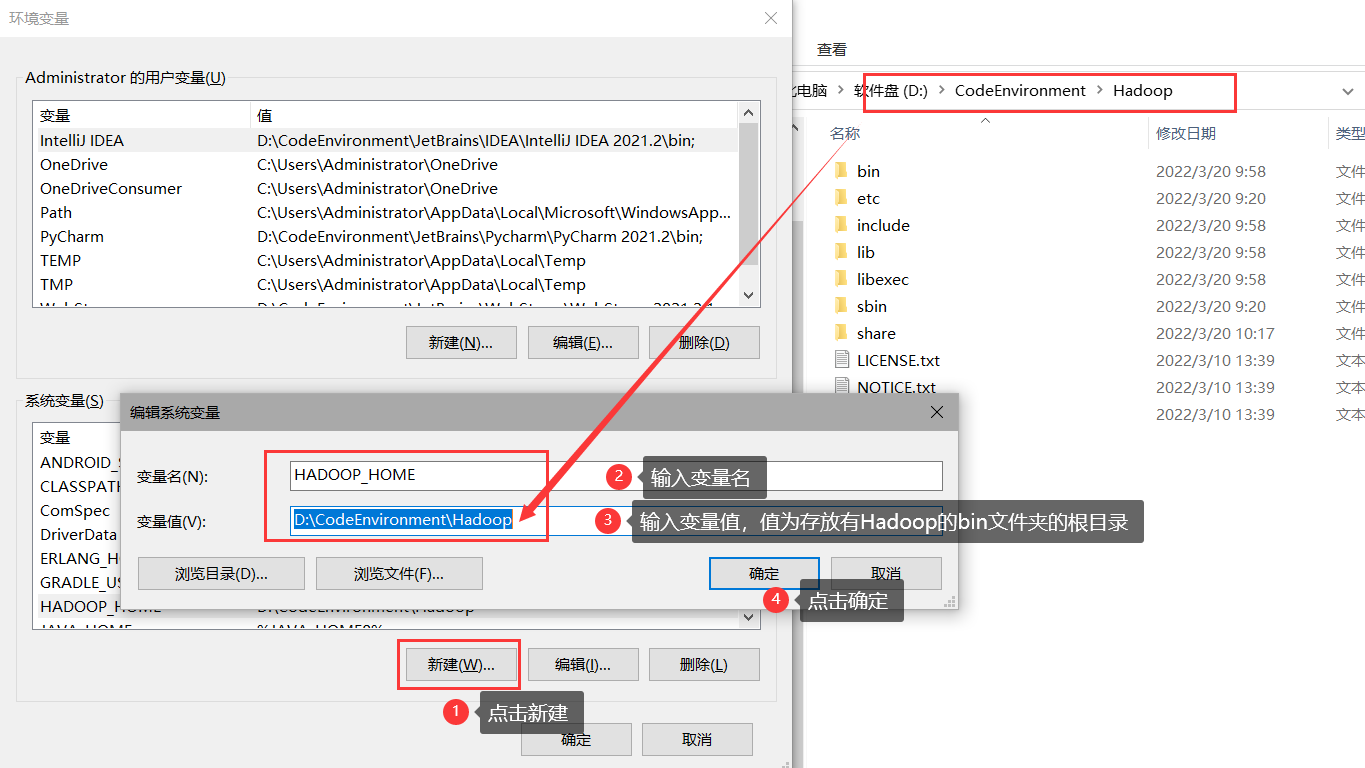 image-202205271849078
image-202205271849078添加到Path变量
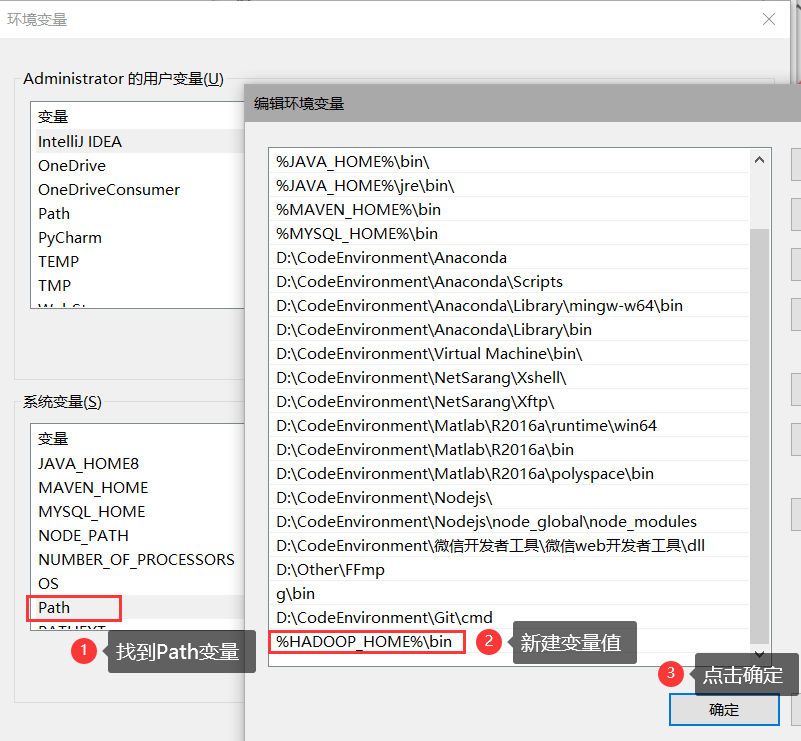 image-20220527185048944
image-20220527185048944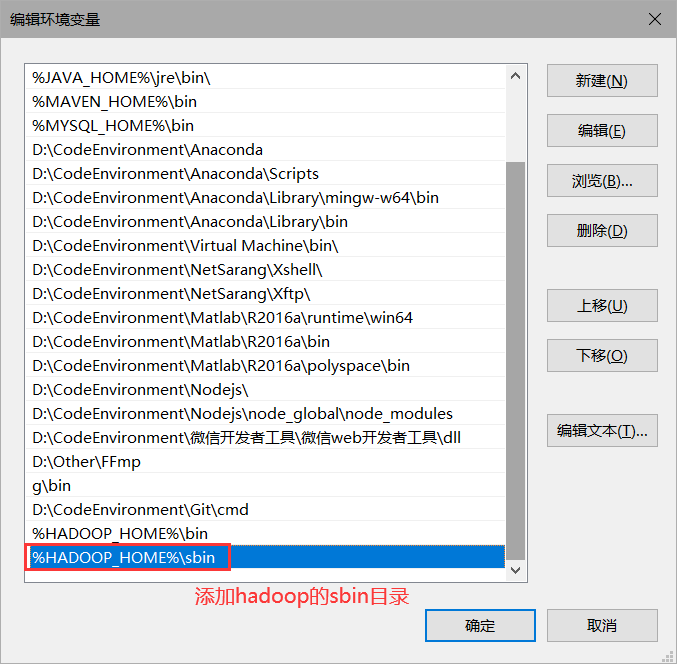 image-20220527190838965
image-20220527190838965然后一路确定即可
此时,我们打开Windows的命令行窗口,输入hadoop测试一下,发现报错
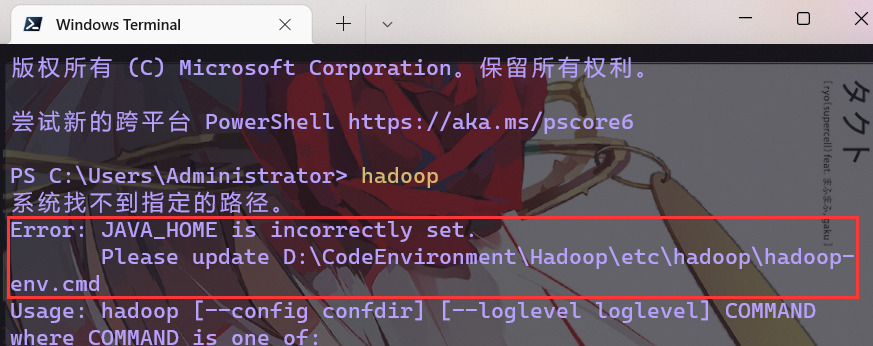 image-20220527185557657
image-20220527185557657根据提示找到这个hadoop-env.cmd文件,使用本文编辑器打开进行如下修改
 image-20220527191541240
image-20220527191541240然后,再次使用hadoop和hadoop -version命令测试,发现未报错
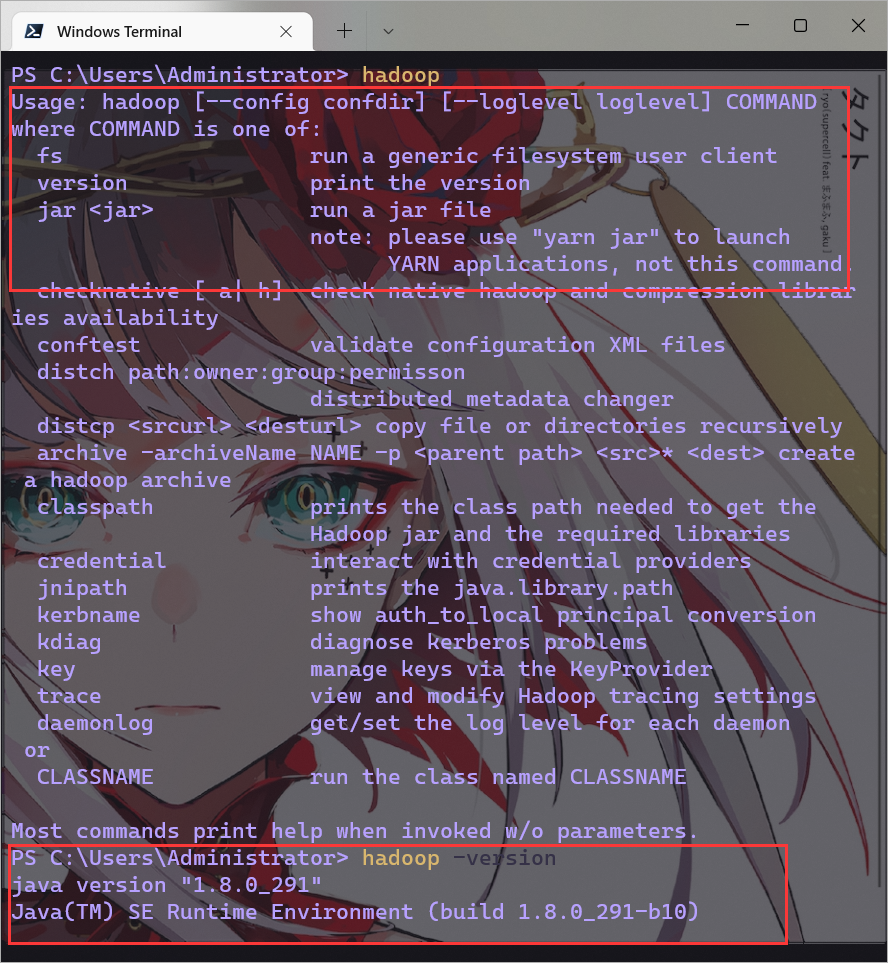 image-20220527191847744
image-20220527191847744输入hadoop -version打印的是jdk的版本,输入hadoop version打印的是hadoop的版本
1.1.4 下载winutils
这是Hadoop在Windows上运行必须要使用的东西
github下载地址和网盘分享地址(提取码: keg8,网盘只提供了3.2.0版本,其他版本请从github上下载)
找到自己hadoop对应的版本,将整个hadoop-xxx\bin文件夹下载下来,然后将这几个文件全部复制到hadoop\bin、hadoop\sbin、C:\Windows\System32这三个文件夹下
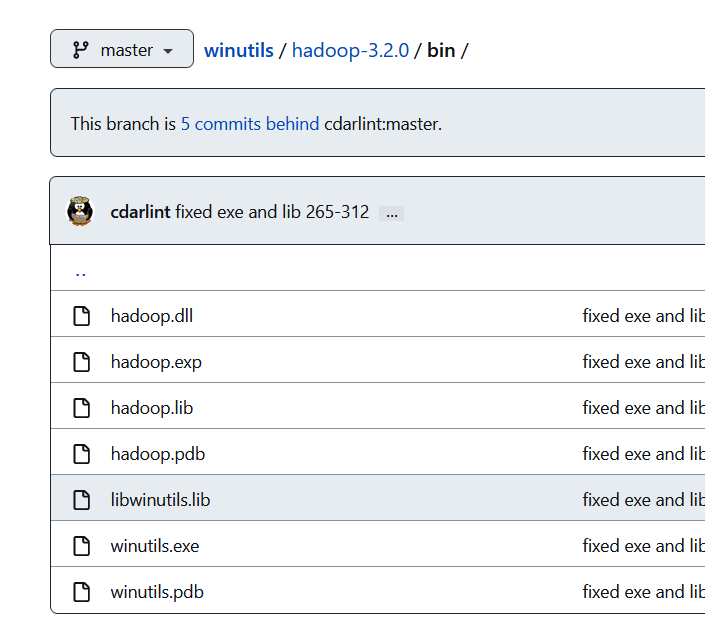 image-20220527193216469
image-202205271932164691.1.5 修改Hadoop配置文件
这一部分跟之前在Ubuntu中搭建Hadoop集群几乎一样,只需要修改一部分地方
由于我们并不是在Windows上使用Hadoop,所以其实在Windows上配置Hadoop环境只需修改需要的即可,比如我们的实验是操作HDFS,那么配置core-site.xml、hdfs-site.xml、mapred-site.xml即可,好像还是几乎都要配置😂(算了,都配置吧🙄),但是有些配置项确实可以不需要
① 配置核心组件core-site.xml
使用文本编辑器打开并编辑core-site.xml文件,在<configuration>标签中添加:
<configuration>
<!--指定HDFS的(NameNode)的缺省路径地址,localhost:是计算机名,也可以是ip地址-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
<!-- 指定hadoop运行时产生文件的存储目录(以个人为准) -->
<property>
<name>hadoop.tmp.dir</name>
<value>/D:/CodeEnvironment/Hadoop/tmp</value> <!--可以自己新建好,也可以等会儿格式化时让其自己创建-->
</property>
</configuration>
② 配置文件系统hdfs-site.xml
使用文本编辑器打开并编辑hdfs-site.xml文件,在<configuration>标签中添加:
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/D:/CodeEnvironment/Hadoop/tmp/dfs/name</value> <!--可以自己新建好,也可以等会儿格式化时让其自己创建-->
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/D:/CodeEnvironment/Hadoop/tmp/dfs/data</value> <!--可以自己新建好,也可以等会儿格式化时让其自己创建-->
</property>
<property>
<name>dfs.namenode.http-address</name>
<value>localhost:50070</value>
</property>
③ 配置文件系统yarn-site.xml
使用文本编辑器打开并编辑yarn-site.xml文件,在<configuration>标签中添加:
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>localhost</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>localhost:18040</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>localhost:18030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>localhost:18025</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>localhost:18141</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>localhost:18088</value>
</property>
<property>
<!--这个是之前在Ubuntu中配置Hadoop集群测试的时候出错添加的,如果不加测试会出现找不到或无法加载主类 org.apache.hadoop.mapreduce.v2.app.MRAppMaster的错误,但是在Windows下还需不需要配置我也不清楚,以防万一我就配置上了,value标签的内容还是一样的获取方法,通过hadoop classpath命令获取,然后将其复制到此处,后面的mapred-site.xml文件中也添加了这个配置,但是name不一样,如果嫌修改路径符号麻烦也可以不添加-->
<name>yarn.application.classpath</name>
<value>/D:/CodeEnvironment/Hadoop/etc/hadoop;D:/CodeEnvironment/Hadoop/share/hadoop/common;D:/CodeEnvironment/Hadoop/share/hadoop/common/lib/*;D:/CodeEnvironment/Hadoop/share/hadoop/common/*;D:/CodeEnvironment/Hadoop/share/hadoop/hdfs;D:/CodeEnvironment/Hadoop/share/hadoop/hdfs/lib/*;D:/CodeEnvironment/Hadoop/share/hadoop/hdfs/*;D:/CodeEnvironment/Hadoop/share/hadoop/yarn;D:/CodeEnvironment/Hadoop/share/hadoop/yarn/lib/*;D:/CodeEnvironment/Hadoop/share/hadoop/yarn/*;D:/CodeEnvironment/Hadoop/share/hadoop/mapreduce/lib/*;D:/CodeEnvironment/Hadoop/share/hadoop/mapreduce/*
</value>
</property>
④ 配置计算框架mapred-site.xml
使用文本编辑器打开并编辑mapred-site.xml文件,在<configuration>标签中添加:
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapred.job.tracker</name>
<value>hdfs://localhost:9001</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>localhost:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>localhost:19888</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=/D:/CodeEnvironment/Hadoop</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=/D:/CodeEnvironment/Hadoop</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=/D:/CodeEnvironment/Hadoop</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>/D:/CodeEnvironment/Hadoop/etc/hadoop;D:/CodeEnvironment/Hadoop/share/hadoop/common;D:/CodeEnvironment/Hadoop/share/hadoop/common/lib/*;D:/CodeEnvironment/Hadoop/share/hadoop/common/*;D:/CodeEnvironment/Hadoop/share/hadoop/hdfs;D:/CodeEnvironment/Hadoop/share/hadoop/hdfs/lib/*;D:/CodeEnvironment/Hadoop/share/hadoop/hdfs/*;D:/CodeEnvironment/Hadoop/share/hadoop/yarn;D:/CodeEnvironment/Hadoop/share/hadoop/yarn/lib/*;D:/CodeEnvironment/Hadoop/share/hadoop/yarn/*;D:/CodeEnvironment/Hadoop/share/hadoop/mapreduce/lib/*;D:/CodeEnvironment/Hadoop/share/hadoop/mapreduce/*
</value>
</property>
1.1.6 格式化HDFS
在命令行窗口输入hdfs namenode -format,如果中间出现提示,输入Y即可
格式化完成后,可以在hadoop的文件夹中看到它已经自动帮我们新建好了之前配置的文件夹(这儿只有name文件夹,没有data文件夹,等会儿启动hadoop后就会出现data)
 image-20220527203001012
image-202205272030010121.1.7 启动Hadoop
在命令行窗口输入start-all.cmd
此时会弹出四个窗口,但是其中有两个窗口报错(如果没有报错就不用管)
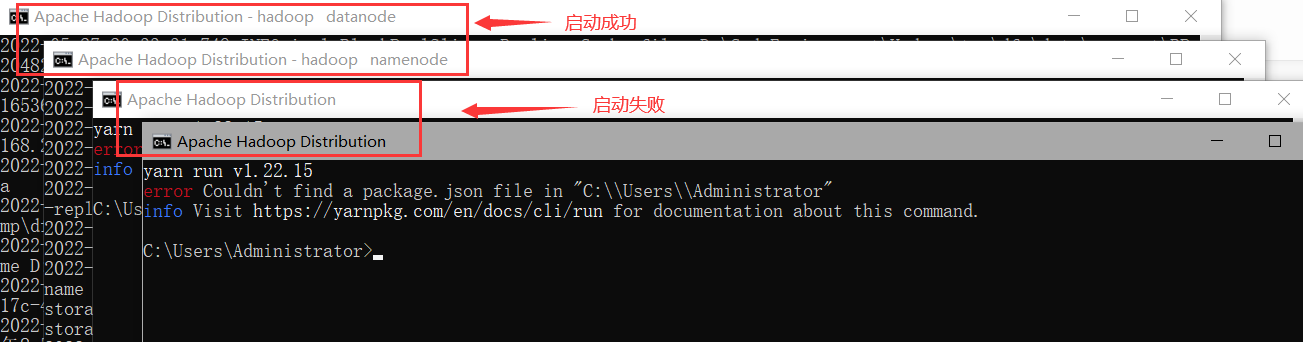 image-20220527204332749
image-20220527204332749出现这个原因是由于我之前安装过node.js,系统里有重名命令yarn,所以在运行hadoop的yarn的时候需要指定其yarn路径,解决办法是打开sbin目录下的start-yarn.cmd文件,修改方式如下:
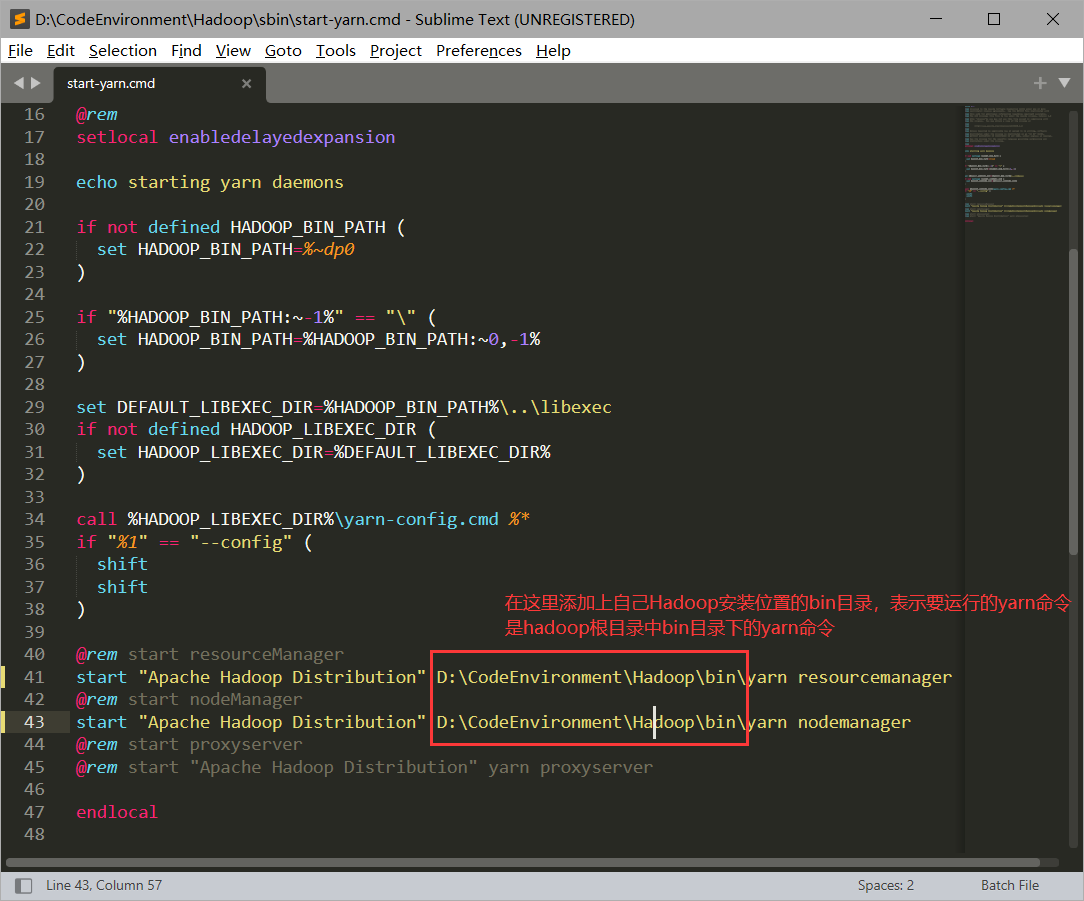 image-20220527205006313
image-20220527205006313此时使用stop-all.cmd停止所有服务后,再start-all.cmd开启所有服务,成功开启
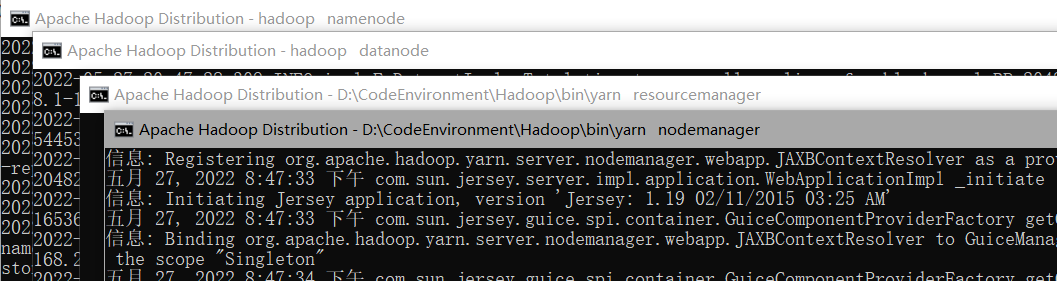 image-20220527205205838
image-20220527205205838使用jps命令查看启动进程
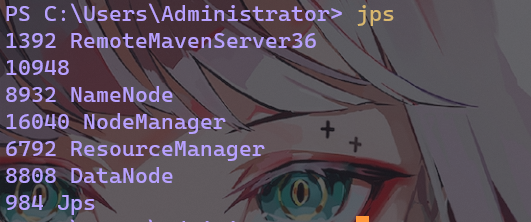 image-20220527205326955
image-20220527205326955在Windows上的浏览器中访问localhost:50070和localhost:18088
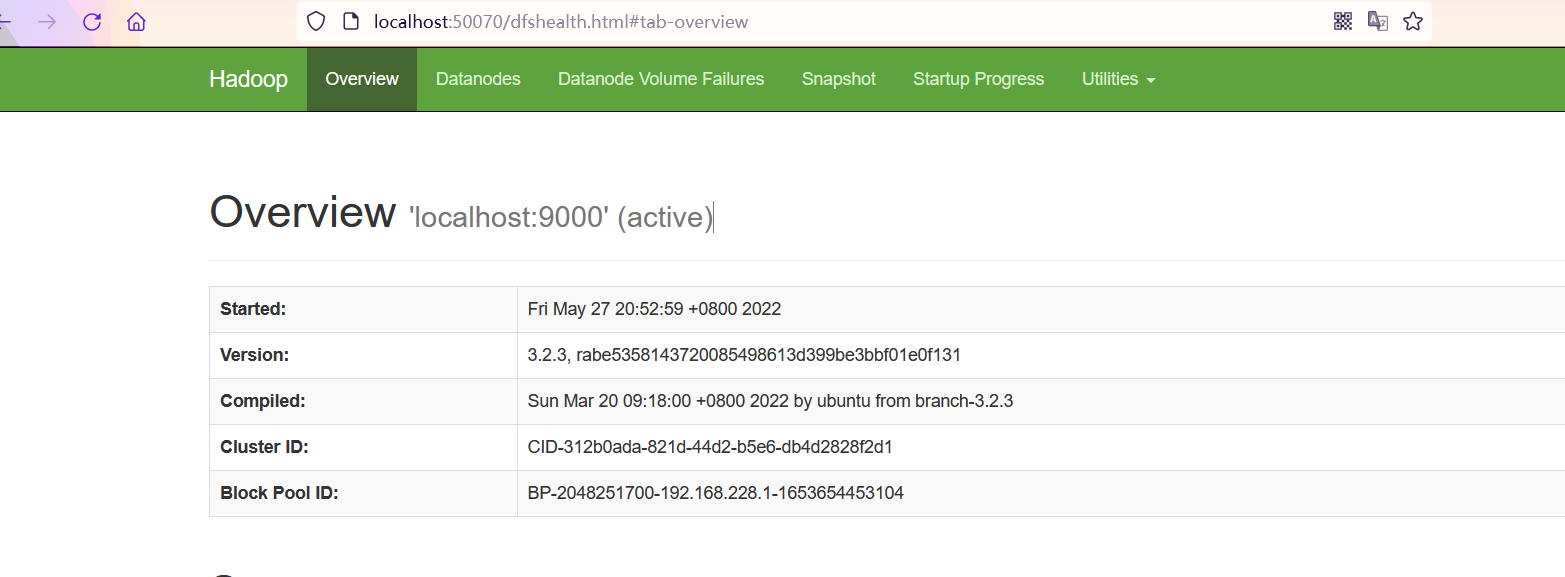 image-20220527205452620
image-20220527205452620 image-20220527205515592
image-20220527205515592到此,Windows上配置Hadoop环境就完成了,这其实也算是一个hadoop单机版的安装步骤了
1.2 Ping
请确保Windows和Ubuntu能够互相ping通
然后,正式开始实验内容
二、实验一:HDFS的文件操作命令及API编程
2.1 HDFS的基本文件操作命令
该小节在Ubuntu中进行操作,如果只安装了单机版当我没说🙄,直接在Windows上操作,把操作的目录名和路径改为windows上的习惯即可
这一小节是书上实验要求的
① 使用start-all.sh启动 hadoop,通过jps命令查看启动进程,下面所有操作都建立在Ubuntu中的Hadoop启动成功的条件下;通过web方式查看namenode和jobtracker,在浏览器输入master:50070和master:18088即可访问,这儿不再赘述
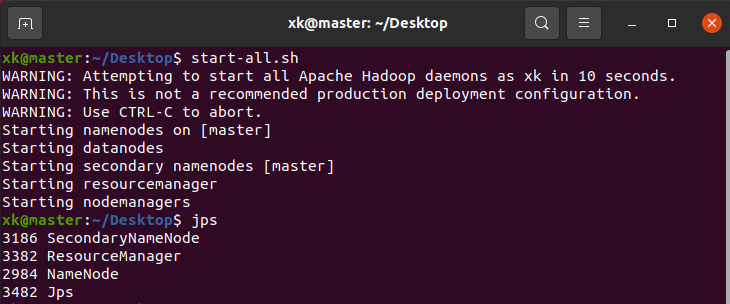 image-20220527211236064
image-20220527211236064② 进入自己Ubuntu中安装hadoop的目录下,进入tmp目录,右键单击选择在终端打开,或者在任意位置的终端中使用cd 要进入的目录命令进入到tmp目录,再使用ls命令查看 hadoop下tmp目录中的文件,包括dfs目录和 mapped目录(不知道为什么没有mapped目录,可能配置文件没配置的原因)
 image-20220527211631172
image-20220527211631172③ 在终端使用hadoop fs -ls /列出HDFS上根目录下的文件和目录,如果从未使用过,那么HDFS中暂无任何目录和文件,就不会输出任何东西
 image-20220528133324311
image-20220528133324311④ 使用命令hadoop fs -mkdir -p /user/xk在HDFS的user目录下创建一个名字盘拼音的目录,并使用hadoop fs -ls -R /查看,加上-R指令就是表示递归查看,会把每一层的每一个文件都显示出来,前面创建目录的-p也基本是同一个意思,表示递归创建
 image-20220528133456084
image-20220528133456084 image-20220528133550169
image-20220528133550169⑤ 在Ubuntu的/usr目录下创建一个test目录,进入test目录,执行echo "hello world" > testl.txt命令创建 test1.txt文件,并输入hello world内容,然后使用cat命令查看内容(创建位置和目录名字随自己而定)
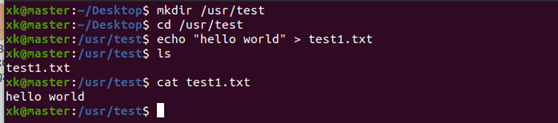 image-20220528134008138
image-20220528134008138⑥ 将刚才在本地创建的 test1.txt文件上传(put)到HDFS下名字的目录下,并查看HDFS的/user/xk目录下是否有test1.txt文件。命令为hadoop fs -put 要上传的文件 要上传到的位置
 image-20220528134253086
image-20220528134253086也可以通过以下方式查看hdfs上的目录和文件
打开浏览器,访问master:50070
 image-20220528134526022
image-20220528134526022点击进入要查看的目录
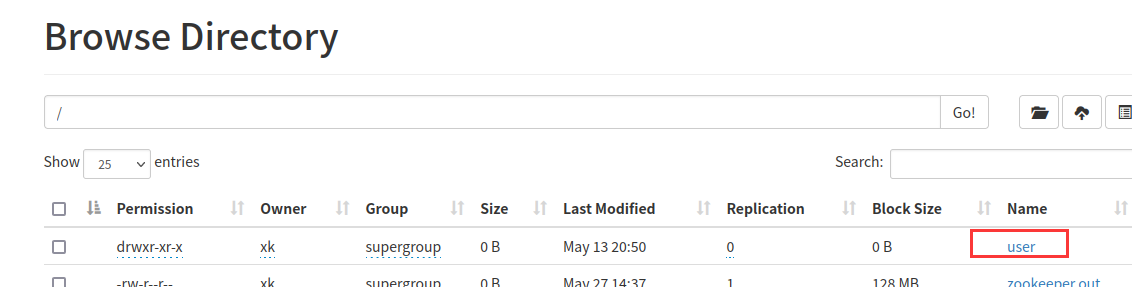 image-20220528134600321
image-20220528134600321⑦ 查看HDFS下刚才上传的文件的内容。命令hadoop fs -cat 要查看的文件
 image-20220528134334624
image-20220528134334624⑧ 彻底删除Ubuntu上刚刚创建的/usr/test目录中的test1.txt文件,删除后可以使用ls确认是否是否成功删除
 image-20220528134830955
image-20220528134830955⑨ 将HDFS上的 test1.txt文件下载到Ubuntu中并查看。下载的命令是hadoop fs -get 要下载的文件 要下载的目录位置,下载到Ubuntu中后使用ls再查看该目录,发现又有了一个test1.txt文件,使用cat查看文件内容
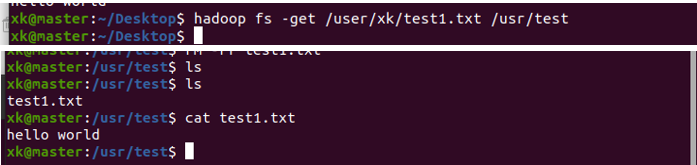 image-20220528135002426
image-20220528135002426⑩ 在HDFS上删除test1.txt文件,命令是hadoop fs -rm -r 要删除的文件,-r或-R表示递归处理,将指定目录下的所有文件与子目录一并处理。删除后再通过ls查看是否还存在
 image-20220528135131667
image-202205281351316672.2 HDFS API编程实验
2.2.1 ResultFilter
编写程序实现如下功能:在输入文件目录下的所有文件中,检索某一特定字符串所出现的行,将这些行的内容输出到本地文件系统的输出文件夹中,也是书上的那个实验
① 首先使用idea新建一个maven项目,这个就不用赘述了
② 在pom.xml文件导入所需要的依赖,为了后面不再重复此操作,这里就把所有要用到的jar包依赖全部导入了(注意:依赖的版本尽量和自己的hadoop版本一致,以免造成版本冲突问题,我用的都是3.2.3,所以我这里就全部使用的3.2.3的版本)
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>3.2.3</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>3.2.3</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.2.3</version>
<exclusions>
<exclusion>
<groupId>io.netty</groupId>
<artifactId>netty</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-common</artifactId>
<version>3.2.3</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>3.2.3</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.13.2</version>
<scope>compile</scope>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase</artifactId>
<version>2.4.11</version>
<type>pom</type>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>2.4.11</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-common</artifactId>
<version>2.4.11</version>
</dependency>
</dependencies>
③ 导入依赖后,新建一个包,再在包下新建一个类ResultFilter(需不需要建包自己随意,只是方便管理),然后复制代码…(真就为了效率直接复制,这也是我自己辛辛苦苦自己打的😭)
同志们,下面的每个程序导包都仔细点,基本都是org.apache.hadoop下的,但还是需要仔细点,可能在不同包下还有相同的类名
public class ResultFilter {
public static void main(String[] args) throws IOException {
Configuration configuration = new Configuration();
//hdfs和local分别对应HDFS实例和本地文件系统实例
FileSystem hdfs = FileSystem.get(configuration);
LocalFileSystem local = FileSystem.getLocal(configuration);
Path inputDir,localFile;
FileStatus[] inputFiles;
FSDataInputStream in;
FSDataOutputStream out = null;
Scanner scan;
String str;
byte[] buf;
int singleFileLines;
int numLines,numFiles,i;
if (args.length!= 4){
//输入参数数量不足,提示参数格式后终止程序执行
System.err.println("usage resultFilter <dfs path> <local path> <match str> <single file lines>");
return;
}
inputDir = new Path(args[0]);
singleFileLines = Integer.parseInt(args[3]);
try {
inputFiles = hdfs.listStatus(inputDir); //获取目录信息
numLines = 0;
numFiles = 1; //输出文件从1开始编号
localFile = new Path(args[1]);
if (local.exists(localFile)) { //若目标路径存在,则删除之
local.delete(localFile,true);
}
for (i = 0;i < inputFiles.length;i++){
if (inputFiles[i].isDir()){//忽略子目录
continue;
}
System.out.println(inputFiles[i].getPath().getName());
in = hdfs.open(inputFiles[i].getPath());
scan = new Scanner(in);
while (scan.hasNext()){
str = scan.nextLine();
if (!str.contains(args[2])){
continue; //如果该行没有match字符串,则忽略之
}
numLines++;
if (numLines == 1){ //如果是1,说明需要新建文件了
localFile = new Path(args[1] + File.separator + numFiles);
out = local.create(localFile); //创建文件
numFiles++;
}
buf = (str + "\n").getBytes();
out.write(buf,0,buf.length);//将字符串写入输出流
if (numLines == singleFileLines){ //如果已满足相应行数,关闭文件
out.close();
numLines = 0; //行数变为0,重新统计
}
}
scan.close();
in.close();
}
if (out != null){
out.close();
}
}catch (IOException e){
e.printStackTrace();
}
}
}
④ 将项目打成jar包
 image-20220528141838720
image-20220528141838720⑤ 在target文件夹下把jar包复制到Ubuntu中,复制过去后可以重命名一下,等会输命令就不用输那么长了,我重命令为BigData.jar
 image-20220528142012378
image-20220528142012378⑥ 在任意位置新建两个文件,并在里面随便输入一些内容,创建文件的命令:touch 文件名
 image-20220528142227183
image-20220528142227183⑦ 将创建好的文件上传到HDFS上,上传后可以通过上面2.1节提到的方法查看是否上传成功
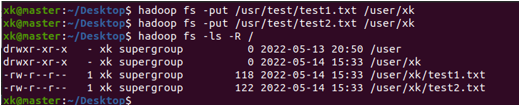 image-20220528142331644
image-20220528142331644⑧ 在终端中运行命令hadoop jar jar包名字 要执行的类名 要检索的文件所在的目录 输出目录 要检索的字符串 每个输出文件所包含的最大行数,我的命令就是hadoop jar BigData.jar experimentone.ResultFilter /user/xk output world 3,表示我要运行的jar包名为BigData.jar,要运行的类名为experimentone包下的ResultFilter类,要检索的文件所在目录是HDFS上的/user/xk,检索输出的文件保存在名为output的目录,要检索的字符串为world,输出文件的最大行数为3(注意自己jar包存放位置,我是因为jar包和终端所在位置都在Desktop才这样写,如果jar包存放位置和终端所处位置不一样,则需要在jar包名字前加上路径,比如/usr/xk/BigData.jar)
 image-20220528143122096
image-20220528143122096运行成功后Ubuntu桌面(不一定是桌面,如果你没指定具体路径,它默认是在你终端现处位置的目录下创建output)多出了一个output目录,里面包含三个文件(文件个数与查询出来的内容总行数、规定的每个文件最大行数有关),分别名为1、2、3,里面的内容就是我检索的目录中所有文件里包含了world的那一行的内容,且每个文件的最大行数为3(我所有操作都是在桌面位置的终端进行,所以output会在桌面,如果想指定具体创建位置和目录名,可以在命令中写详细点)
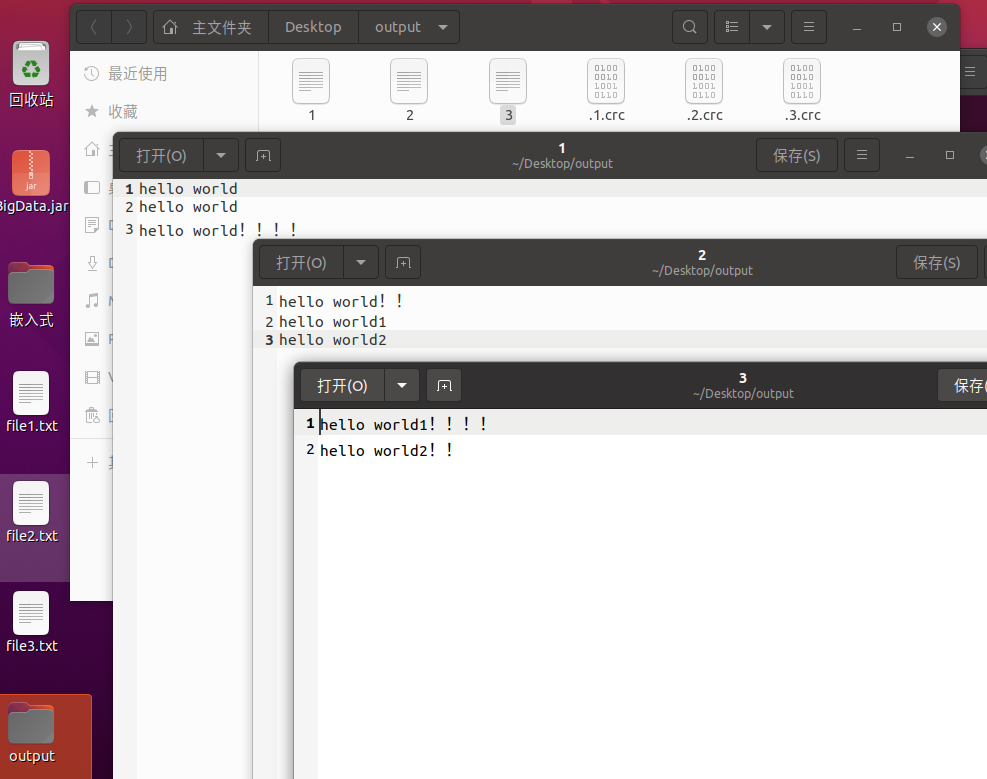 image-20220528143353939
image-202205281433539392.2.2 CreateDirectory
这个是老师给出拓展实验之一,实验目的就是在HDFS上面创建一个目录
省去上面提到的导入依赖的步骤,直接在包下新建一个名为CreateDirectory的类
然后,代码如下:
public class CreateDirectory {
private static final String hostString = "hdfs://master:9000";
public static void main(String[] args) throws IOException {
Configuration conf = new Configuration();
conf.set("fs.default.name", hostString);
FileSystem hdfs = FileSystem.get(conf);
if(hdfs.exists(new Path("hdfs:/myTestDirectory"))){
System.out.println("目录已经存在!,先删除");
hdfs.delete(new Path("hdfs:/myTestDirectory"),true);
}else {
boolean isok =hdfs.mkdirs(new Path("hdfs:/myTestDirectory"));
if(isok)
System.out.println("目录创建成功!");
else
System.out.println("目录创建失败!");
}
hdfs.close();
}
}
然后,依旧是点击侧边栏的Maven,这次首先点击clean将刚刚编译的内容清除,再点击package将项目打包,再复制到Ubuntu中
这样似乎很麻烦,因为每次我们新建一个类去完成另一个实验都要进行这样的操作,所以我建议把所有代码敲完了再把整个项目打成jar包复制到Ubuntu中,比如像这样:
 image-20220528144604203
image-20220528144604203继续上面的步骤,将jar包复制到Ubuntu中后,我们使用命令hadoop jar BigData.jar experimentone.CreateDirectory 执行该程序,然后我们可以通过hadoop fs -ls /查看是否真正创建成功,也可以通过上面提到的通过web方式进行查看
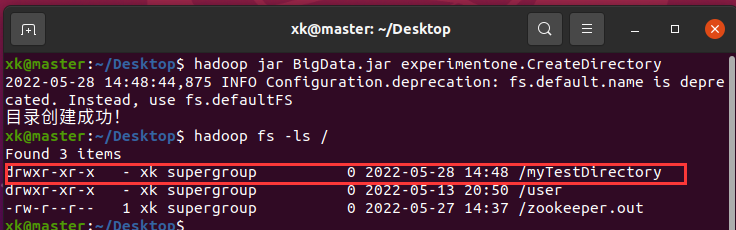 image-20220528144937444
image-202205281449374442.2.3 HdfsClient
这个也是老师给出的拓展实验之二,实验目的是通过Windows下的IDEA模拟HDFS客户端来操作Ubuntu中的HDFS
在准备工作中我们在Windows下安装Hadoop就是为了这个实验
同样,新建一个名为HdfsClient的类,代码如下:
public class HdfsClient {
FileSystem fs = null;
//连接hdfs集群
@Before
public void init() {
Configuration conf = new Configuration();
System.out.println("执行Before!");
try {
fs = FileSystem.get(new URI("hdfs://master:9000/"), conf, "xk");//xk改成自己虚拟机的用户名,如果单独为hadoop创建一个用户,则修改为hadoop的用户名
} catch (IOException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (URISyntaxException e) {
e.printStackTrace();
}
}
//下载数据 hdfs->本地
@Test
public void hdfsGet() {
try {
fs.copyToLocalFile(new Path("/zookeeper.out"), new
Path("e:/zookeeper.out"));
fs.close();
} catch (IOException e) {
e.printStackTrace();
}
}
//上传数据 本地上传到hdfs集群
@Test
public void localToHdfs() {
try {
fs.copyFromLocalFile(new Path("e:/new2.txt"), new Path("/new2.txt"));
fs.close();
} catch (IOException e) {
e.printStackTrace();
}
}
//hdfs中创建文件夹
@Test
public void hdfsMkdir() {
try {
fs.mkdirs(new Path("/hdfs-clientTest"));
fs.close();
} catch (IOException e) {
e.printStackTrace();
}
}
//在hdfs中移动修改文件
@Test
public void hdfsRename() {
try {
fs.rename(new Path("/zookeeper.out"), new Path("/zookeeperXK.out"));
fs.close();
} catch (IOException e) {
e.printStackTrace();
}
}
//删除文件夹
@Test
public void deleteDir() {
try {
fs.delete(new Path("/hdfs-clientTest"), true);
fs.close();
} catch (IOException e) {
e.printStackTrace();
}
}
/*
* 查询hdfs下指定目录下的信息
*/
@Test
public void hdfsLs() throws Exception {
//只查询文件的信息不返回文件夹的信息
RemoteIterator<LocatedFileStatus> iter = fs.listFiles(new Path("/"), true);
//如果有数据
while (iter.hasNext()) {
//取
LocatedFileStatus status = iter.next();
System.out.println("文件路径为:" + status.getPath());
System.out.println("块大小为:" + status.getBlockSize());
System.out.println("文件长度为:" + status.getLen());
System.out.println("副本数量为:" + status.getReplication());
System.out.println("块信息为:" +
Arrays.toString(status.getBlockLocations()));
//分割线
System.out.println("==================================");
}
fs.close();
}
/*
* 查询hdfs下指定目录下的文件和文件夹信息
*/
@Test
public void hdfsLs2() throws Exception {
//展示状态信息
FileStatus[] listStatus = fs.listStatus(new Path("/"));
for (FileStatus ls : listStatus) {
System.out.println("文件路径为:" + ls.getPath());
System.out.println("块大小为:" + ls.getBlockSize());
System.out.println("文件长度为:" + ls.getLen());
System.out.println("副本数量为:" + ls.getReplication());
System.out.println("==================================");
}
fs.close();
}
}
这个实验不需要将项目打成jar包在Ubuntu下运行,而是直接在Windows下操作
但是,在这之前,我们需要在Ubuntu中创建文件,并将其上传到hdfs上。touch创建文件,vi 编辑文件,hadoop fs -put XXX XXX上传文件,hadoop fs -ls /查看文件,我这儿是将当前目录下的zookeeper.out文件上传到了HDFS的根目录中
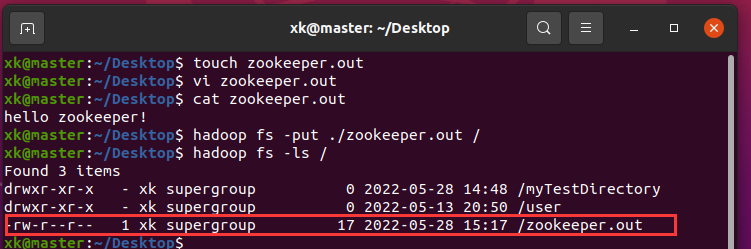 image-20220528151905054
image-20220528151905054另外,我们在Windows上也需要随意新建一个文件,一会儿会通过HdfsClient将其上传到HDFS上,文件名和存放路径不同也要修改HdfsClient中相应的代码片段
现在开始执行单元测试程序
① 下载数据 hdfs -> Windows本地,执行hdfsGet()方法
执行完成后,可在自己Windows上对应位置查看到下载下来的文件,比如,我的就是在e:/zookeeper.out
 image-20220528153028597
image-20220528153028597运行过程中出现以下提示不用担心,这是因为hadoop的相关依赖又依赖了log4j这个日志jar包,项目如果有这个依赖但是没有其配置文件就会报错,我们不需要查看日志就不用管,如果有强迫症非要消掉报错,可以在网上搜一下log4j的配置文件,将其添加到项目的resource文件夹下即可
 image-20220528153858942
image-20220528153858942② 上传数据 Windows本地 -> hdfs,执行localToHdfs()方法
执行成功后,可以在web端的hdfs进行查看,我在本地创建new2.txt文件被上传到了hdfs上
 image-20220528153656938
image-20220528153656938③ hdfs中创建文件夹,执行hdfsMkdir()方法
执行成功,以同样的方式查看
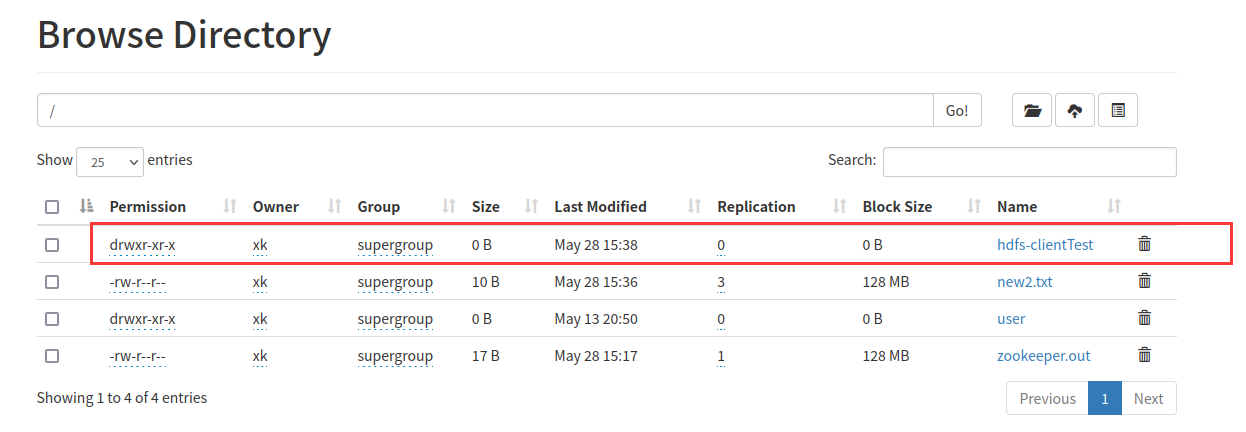 image-20220528153936498
image-20220528153936498④ 在hdfs中移动修改文件,执行hdfsRename()方法
执行成功后,可以发现zookeeper.out文件被重命名
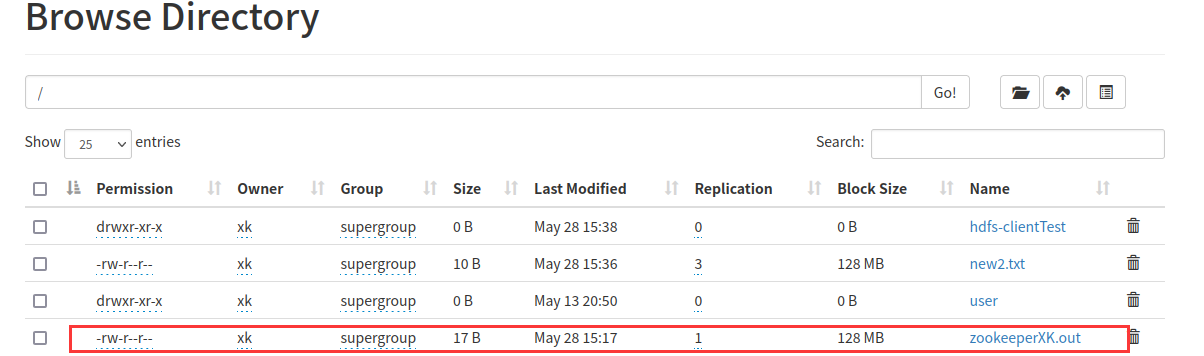 image-20220528154158891
image-20220528154158891⑤ 删除文件夹,执行deleteDir()方法
执行成功后,hdfs-clientTest目录就会被删掉
⑥ 查询hdfs下指定目录下的信息,执行hdfsLs()方法
执行完成后,idea的终端会输出打印HDFS中指定目录下(我们程序中是要查询出根目录下的)所有文件的相关信息
 image-20220528154508742
image-20220528154508742⑦ 查询hdfs下指定目录下文件和文件夹的信息,执行hdfsLs2()方法
执行完成后,会打印出hdfs中指定目录下的文件和文件夹相关信息
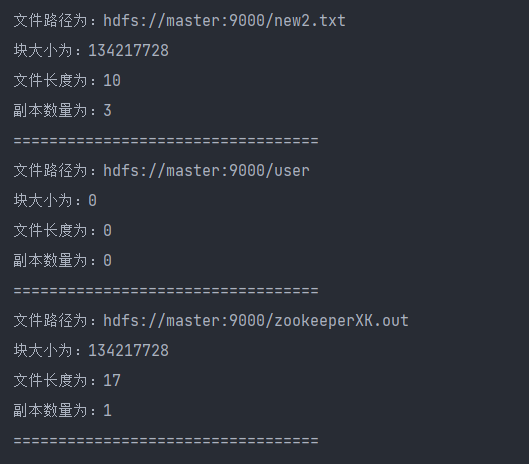 image-20220528155054407
image-20220528155054407三、实验二:IDEA下的MapReduce编程
3.1 WordCount
这是书上的实验
在开始这个实验之前需要上传一个新的文件到HDFS上,并且里面要包含一些内容,这个实验的目的就是为了统计这个文件中各个单词的个数
准备工作操作参考:
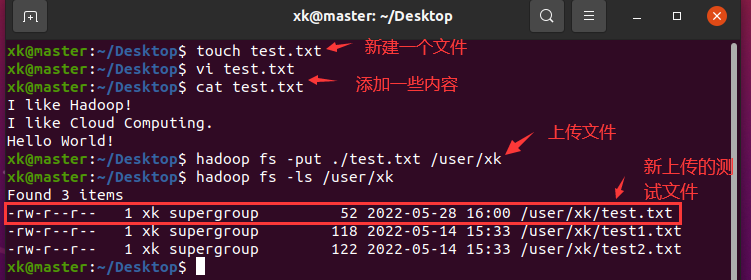 image-20220528160147121
image-20220528160147121省去新建项目和导入依赖的步骤,直接新建一个名为WordCount的类
实验代码如下:
public class WordCount {
public static void main(String[] args) throws Exception{
Configuration conf = new Configuration();
//以下这些配置都见名知意,不用解释吧
conf.set("fs.default.name","hdfs://192.168.228.128:9000");//ip改为自己虚拟机的
conf.set("mapred.job.tracker","192.168.228.128:9001");
conf.set("hadoop.job.user","xk");//xk改为自己的
String[] ars = new String[]{"input","output"};
String[] otherArgs = new GenericOptionsParser(conf, ars).getRemainingArgs();
if (otherArgs.length != 2){
System.err.println("Usage:wordcount ");
System.exit(2);
}
Job job = new Job(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//添加hdfs上我们要统计的文件
FileInputFormat.addInputPath(job,new Path("hdfs://192.168.228.128:9000/user/xk/test.txt"));
//设置统计结果输出目录(依然是存放在hdfs上的)
FileOutputFormat.setOutputPath(job,new Path("hdfs://192.168.228.128:9000/user/xk/output"));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key,Text value, Context context) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()){
word.set(itr.nextToken());
context.write(word,one);
}
}
}
public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable>{
private IntWritable result = new IntWritable();
public void reduce(Text key,Iterable<IntWritable> values,Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key,result);
}
}
}
同样,将项目打成jar包(如果不是一次性将所有程序写好后打的jar包请记得先clean再package),复制到Ubuntu中,然后使用命令hadoop jar 要运行的jar包 要运行的类名运行该程序
 image-20220528161615949
image-20220528161615949等过一会儿运行完成后,终端大概是这样的
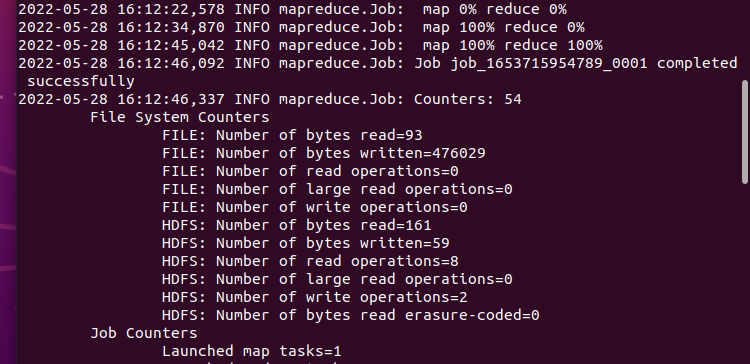 image-20220528161658397
image-20220528161658397通过web端查看,可以看到多出一个output目录
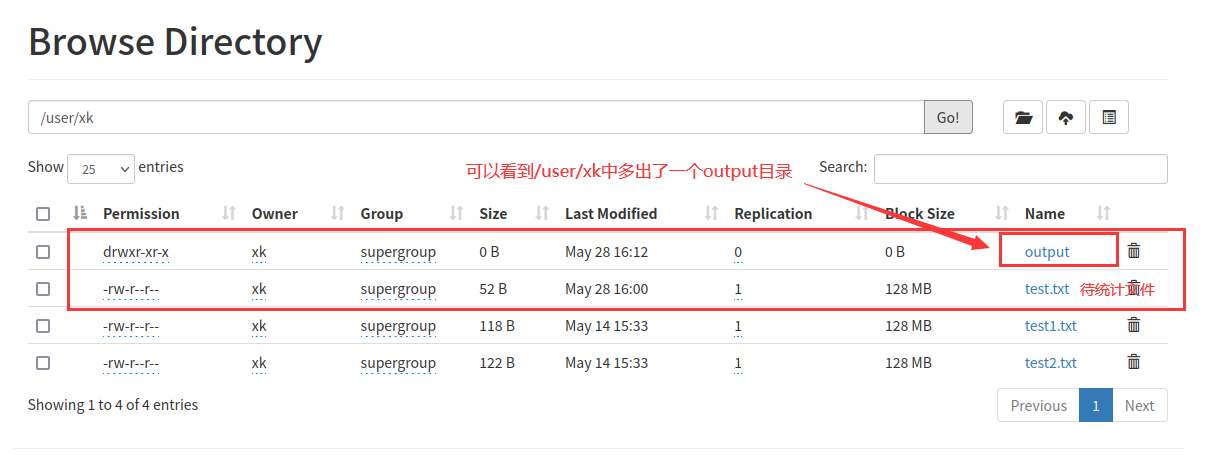 image-20220528161848081
image-20220528161848081output的生成位置取决于在程序中的此处的设置:
 image-20220529183816805
image-20220529183816805进入到output目录中,可以看到两个文件
 image-20220528162015041
image-20220528162015041我们将这个目录下载下来查看
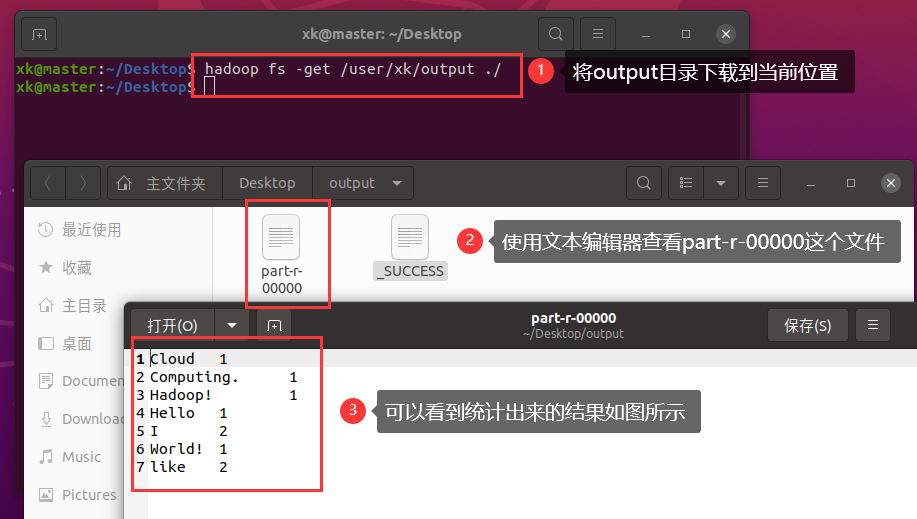 image-20220528162401811
image-202205281624018113.2 InvertedIndex
这是实验二老师给出的扩展实验
开始实验之前,请先将课上老师发的三个文件复制到Ubuntu中
 image-20220528163756886
image-20220528163756886然后,在Ubuntu中的HDFS上创建几个目录,InvertedIndex和InvertedIndex/input
然后,将那三个文件上传到input目录中
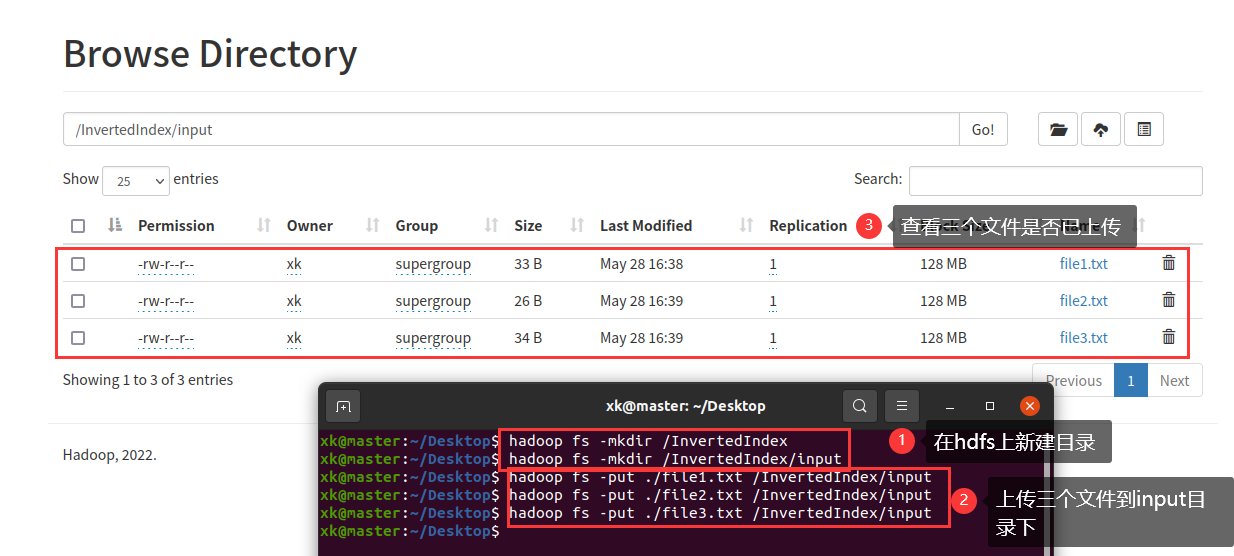 image-20220528164046576
image-20220528164046576然后在项目中新建几个类,分别为InvertedIndexCombiner、InvertedIndexMapper、InvertedIndexReducer、InvertedIndexRunner
public class InvertedIndexCombiner extends Reducer<Text, Text, Text, Text> {
private static Text info = new Text();
// 输入: <MapReduce:file3 {1,1,...}>
// 输出:<MapReduce file3:2>
@Override
protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
int sum = 0;// 统计词频
for (Text value : values) {
sum += Integer.parseInt(value.toString());
}
// 查找分隔位置
int splitIndex = key.toString().indexOf(":");
// 重新设置 value 值由 URL 和词频组成
info.set(key.toString().substring(splitIndex + 1) +":"+sum);
// 重新设置 key 值为单词
key.set(key.toString().substring(0,splitIndex));
context.write(key,info);
}
}
public class InvertedIndexMapper extends Mapper<LongWritable, Text, Text, Text> {
// 存储单词和文件明组合
private static Text keyInfo = new Text();
// 存储词频,初始化为
private static final Text valueInfo = new Text("1");
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, Text>.Context context) throws IOException, InterruptedException {
String line = value.toString();
// 得到字段数组
String[] fields = StringUtils.split(line, ' ');//别用双引号
// 得到这行数据所在的文件切片
FileSplit fileSplit = (FileSplit) context.getInputSplit();
// 根据文件切片得到文件名
String fileName = fileSplit.getPath().getName();
for (String field : fields) {
// key值由单词和URL组成,如“MapReduce:file1”
keyInfo.set(field + ":" + fileName);
context.write(keyInfo, valueInfo);
}
}
}
public class InvertedIndexReducer extends Reducer<Text, Text, Text, Text> {
private static Text result = new Text();
// 输入:<MapReduce file3:2>
// 输出:<MapReduce file1:1;file2:1;file3:2;>
@Override
protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
// 生成文档列表
String fileList = new String();
for (Text value : values) {
fileList += value.toString() + ";";
}
result.set(fileList);
context.write(key, result);
}
}
public class InvertedIndexRunner {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
//配置RM地址
conf.set("fs.default.name", "hdfs://192.168.228.128:9000");
conf.set("mapred.job.tracker", "192.168.228.128:9001");
conf.set("hadoop.job.user","xk"); //构建Job实例
Job job = Job.getInstance(conf);
//为Job设置类名
job.setJarByClass(InvertedIndexRunner.class);
//为Job设置Mapper类
job.setMapperClass(InvertedIndexMapper.class);
//为Job设置Combiner类
job.setCombinerClass(InvertedIndexCombiner.class);
//为Job设置Reducer类
job.setReducerClass(InvertedIndexReducer.class);
//为Job的输出数据设置Key类
job.setOutputKeyClass(Text.class);
//为Job输出设置value类
job.setOutputValueClass(Text.class);
//为Job设置输入路径
FileInputFormat.setInputPaths(job, new Path("hdfs://192.168.228.128:9000/InvertedIndex/input"));
// 指定处理完成之后的结果所保存的位置
FileOutputFormat.setOutputPath(job, new Path("hdfs://192.168.228.128:9000/InvertedIndex/output"));
// 向 YARN 集群提交这个 Job
boolean res = job.waitForCompletion(true);
System.exit(res ? 0 : 1);
}
}
同样,将项目打成jar包,复制到Ubuntu中,然后使用命令hadoop jar 要运行的jar包 要运行的类名运行该程序
程序运行完后,在hdfs的/InvertedIndex目录下多出了一个output目录
我们同样也可以下载下来查看
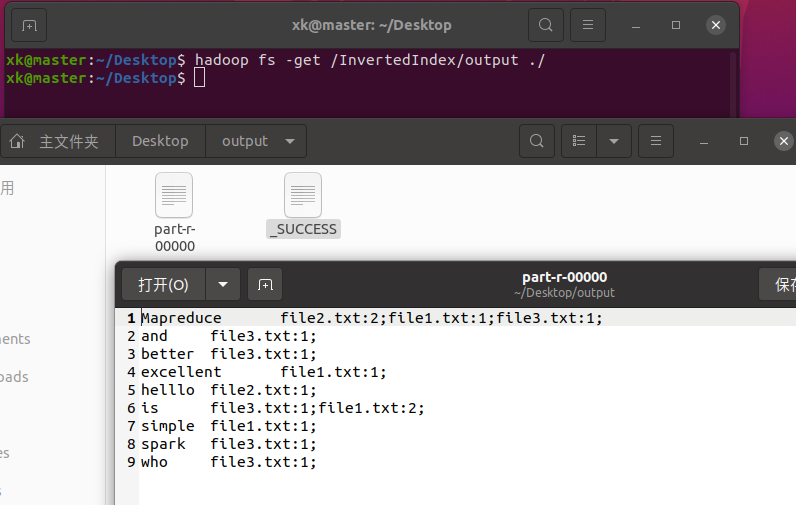 image-20220528164553511
image-20220528164553511到此,本学期所有的课程实验就都完成了,其实这些实验都很简单,毕竟代码都是现成的,我们只需要能运行出来就行,就是配置环境麻烦
最后,希望大家都能准确无误地运行出来,有问题和疑惑可以QQ私聊我或在下面评论



